

数据知识化:迈出“构建以AI为中心”工作流的第一步
信任危机
高质量知识——扎根核心业务的唯一银弹
这几年,AI 大模型无疑是科技圈最热闹的风口。对话闲聊、文案生成、日常咨询,各类应用早已随处可见,给人一种 “AI 已经无所不能” 的错觉。但褪去流量热度,下沉到真实产业场景就会发现:热闹都在通用场景,硬核行业依旧保守。金融风控、医疗诊疗、政务办事、工业生产这些关乎合规、安全、责任的核心领域,大模型难以插手,最后只能在 chat 助手、简单咨询这些场景里打转。
背后还有一层更隐蔽的现实:**企业沉淀几十年的业务文档与工作流程,从一开始就不是为 AI 读取设计的。**常见的合同、报告、操作手册其中的排版版式、图文表格、批注签章、格式注解,全都是围绕“人看得懂、看着舒服”打造的,这套人类适配的版式逻辑,反倒成了机器理解内容的天然阻碍。
不止文档适配有隔阂,这类行业还有一条绝不能触碰的底线:**核心业务零容错。**一句客服答复出错、一份病历遗漏关键信息、一次政策解读引用废止条文,出错的代价远不止体验不佳,更会触发合规追责、透支用户信任,极端情况下甚至直接拖垮整条业务链路。
Gartner 在《2025 年中国数据、分析和人工智能技术成熟度曲线》里对这早已给出定论:大模型可靠性不足、幻觉频发,是它难以进入企业核心场景的关键障碍。报告里 Gartner 分析师闫斌还专门点出行业普遍存在的 “Agent Washing”(贴牌智能体) 现象:把普通聊天机器人包装成所谓”智能体”,背后没有真正的知识支撑,谈不上做决策[1]。
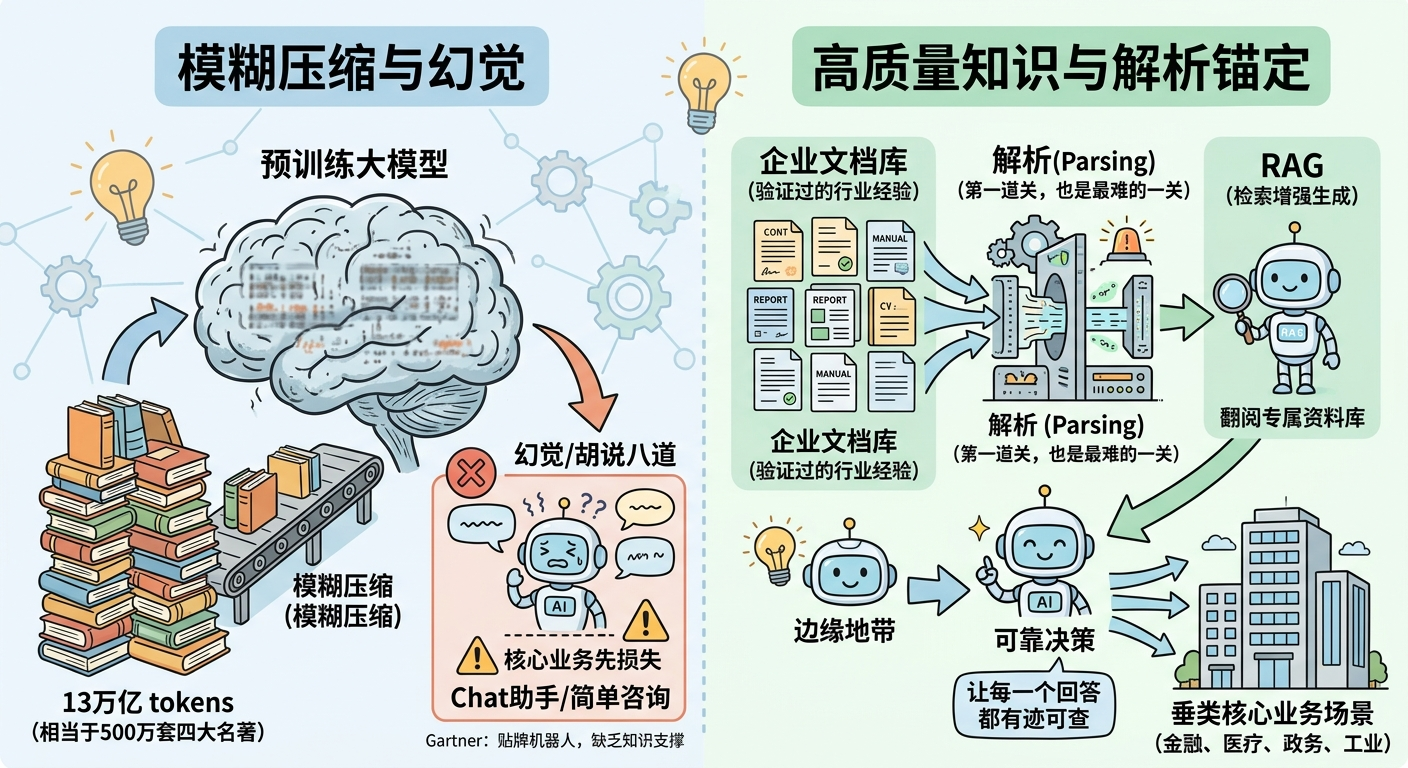
问题的根本在于:大模型学的是怎么说话,不是事实是什么。《人民日报》做过一个比方[2]:大模型预训练数据能到 13 万亿 token,差不多顶 500 万套四大名著。DeepSeek V3 达到 14.8T,2026 年 4 月发布的 V4-Pro / V4-Flash 直接拉到 33T / 32T tokens[3],相当于 1200 多万套四大名著。但这么大的信息量被”压缩”进有限的参数里之后,输出时反而特别容易一本正经地胡说八道,也就是常说的 AI 幻觉。
破局点只有一个:高质量知识。 让模型在回答之前先去翻一遍”专属资料库”,而不是靠印象瞎编,这正是 RAG(检索增强生成)这两年迅速铺开的原因。
这两年行业早已形成共识:模型从来不是真正的瓶颈,数据才是。微软 Phi-3/Phi-4 系列就是最好的例子 —— 靠 “教科书级” 的高质量语料训练,仅 4B 参数的小模型,在多项权威评测上直接干翻参数体量大自己几十倍的通用大模型[4],这足以证明:**数据质量的杠杆效应,远大于盲目堆参数。**Forbes 2026 年那篇被反复转引的评论标题更直接——《世界级算法栽在二流数据上》[5]:企业落地失败的真正原因,几乎都不是模型选错了,而是喂进去的数据本身就不干净、不结构化、不可追溯。
Garbage in, hallucinations out. 无论模型迭代到什么级别,若原始数据杂乱无章、未经规整,最终输出难逃幻觉缠身。
而企业最可靠的资料库,往往就在自己手上。几十年攒下来的业务经验,绝大多数都落在文档里:合同里是条款,报告里是数据,论文里是方法,手册里是规程。这些东西经过人来回核过、在真实业务里跑过,可信度本来就比训练语料高一截。
解析,就是这场知识化旅程的第一道关:把散落各处的文件,转化为 AI 真正能用的知识输入。今天的文档之所以需要被”读懂”,是因为它们一开始就不是写给机器看的。未来某天,当企业的工作流真正围绕 AI 重新设计,文档或许会直接以机器友好的形式生成,解析这道工序也会被重新定义,甚至退到幕后。但在那一天到来之前,几十年、上百亿份”人类格式”的资料摆在那里,必须被重新读懂一遍。这件事没有捷径——这就是解析在当下不可或缺的理由。
解析——AI 的”视网膜”
人类眼中的光不是知识,是视网膜与视觉皮层的”解析”,才让光成为”世界”
“解析”这个词,连业内人士都没统一过叫法。
LangChain 管它叫 loader(加载器),强调”把东西搬进来”的动作;学术论文和技术文档里则习惯叫 parser,强调”把东西拆开看清楚”的过程。一个盯着起点,一个盯着过程,两个名字都没错,只是各自抓住了解析的一条腿。
把两条腿合在一起,才是解析的全貌:通过技术手段,将非结构化或半结构化数据(PDF、Word、图片、表格、音频……)提取、分析、转换,变成机器能理解、能处理的结构化知识,并为后续 AI 应用提供标准化的知识输入。
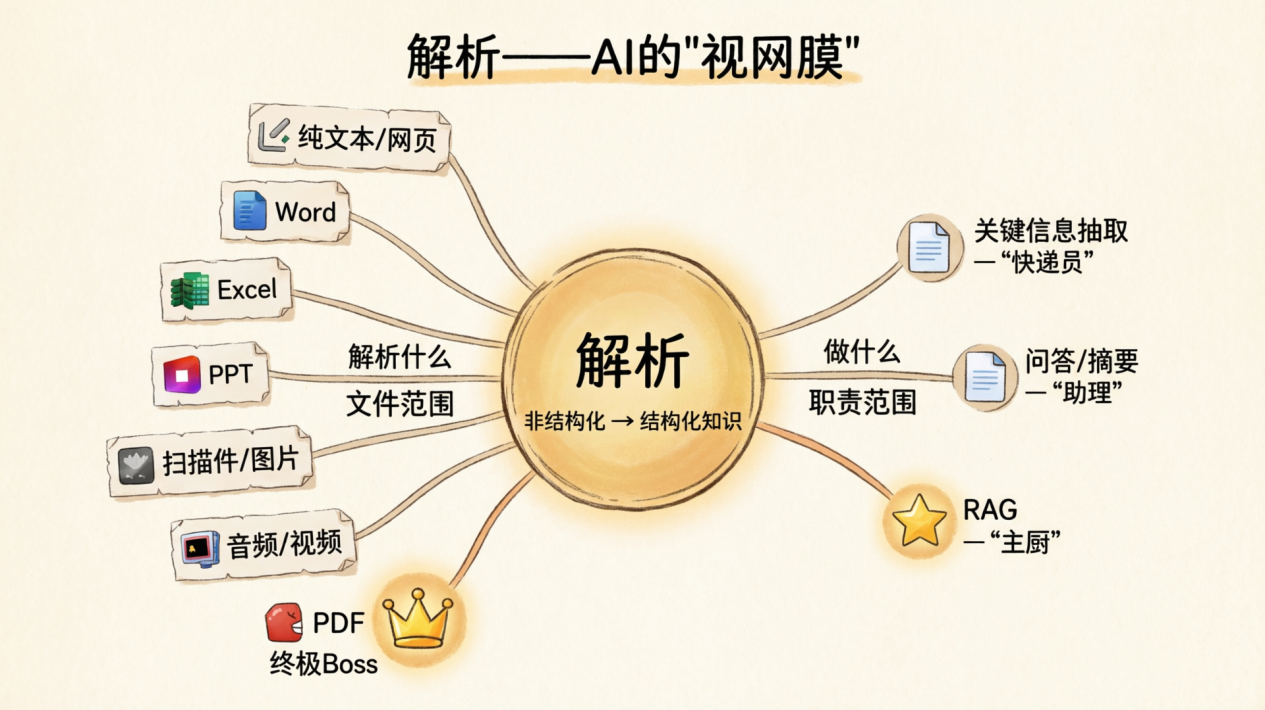
文件范围
只要人类写过字的地方,解析都得想办法读懂。但每种文件的特性差得很远,并且有条反直觉的规律:越是”给人看着舒服”的格式,往往越难让机器读懂。
• 纯文本 / 网页:最省心的一类。有标签、有结构,按照既定的规则直接读取就行。
• Word(DOCX):典型的“表面光鲜”类型。内容和样式彻底拆分存储、表格无限嵌套层级、图文混排随心所欲,排版逻辑全靠 Office 自家规则兜底。外人看着整整齐齐,机器解析时根本摸不清文本、图表、版式之间的从属关系,拆结构堪比拆一团缠死的耳机线。
•** Excel(XLSX)**:表格看着简单,实则一坑一个不吱声。合并单元格的值只存在左上角那一格、隐性合并单元格、多工作表关联混杂、单元格跨行列逻辑错乱、空白行列干扰结构识别,再加上混搭格式、隐藏行列干扰字段对齐。
• PPT(PPTX):自由画布 =解析重灾区。文字框想摆哪儿就摆哪儿,没有天然阅读顺序,机器不知道从哪儿读起,只能盲目遍历。
• 扫描件 / 图片文字:大量历史档案、法律文件、学术出版物到今天还以扫描件形式躺着,是数字化没追上的历史欠账,不是有人故意刁难机器。对机器来说,这类文件等于眼前一片黑,只能靠 OCR “硬猜”,错别字和断句是家常便饭。
• 音频 / 视频:解析界的新晋“天花板”,也是最不省心的一类。音频要先把声音转成文字(ASR),再分辨谁在说、说了什么;视频更夸张:画面轨、音频轨、字幕轨多源信息交织耦合,不是单一条线索,而是多维度信息要对齐融合。当下越来越多企业把会议录音、培训视频、客服通话等沉淀为私有知识库,也倒逼解析能力快速补齐短板。
•** PDF**:看着最通用,实则解析界的终极 Boss。
全球每天流转的合同、报告、论文、票据,绝大多数都是 PDF,谁都能打开,谁都看得懂。但 PDF 实际上”只管画面、不管结构”:它只记得每个字符该画在哪个坐标,至于”这是标题""那是段落""这块是表格”,它完全不管。
也因此,后文所有的技术讨论都默认对象是 PDF。一方面它本来就是企业文档的绝对主流,另一方面解析会遇到的那些典型难题(字体、版式、表格、公式、扫描件、图文混排)几乎都能在 PDF 身上集齐。
职责范围
解析在不同场景里,工作范围和承担职责差距很大。
举个不太恰当的例子,就像”厨师”这个词:有人只负责备菜,有人要从采购到摆盘全包。解析也一样,场景不同,职责边界也是天差地别:

RAG,才是解析的重头戏
在 RAG 中,解析不只是”把文件内容读出来”,更要在读的过程中保留元素之间的结构关系:文字、公式、表格、图像并不是孤立的,它们的位置关系、层级关系本身就是知识的一部分。把”线性排列的文字”变成”AI 能检索的结构化知识”,是两件本质不同的事。具体说:
• 章节→ 层级关系
• 段落→ 语义块(大小要刚好,不能太大也不能太小)
• 表格→ 键值对 / 关系
• 公式 / 代码 → 特殊语义单元
• 图表→ 描述性知识
结构化之后,还有一步:切片,把长文档切成合适大小的”知识块”,再送入向量库供检索。切得好不好,直接决定 AI 能不能找到、找准、用对知识:
• 块太大→ AI 记忆模糊,说话含糊其辞
• 块太小→ AI 记忆碎片化,东拼西凑答非所问
• 无结构→ 检索不到
• 有噪声(页眉页脚、乱码、广告残留)→ AI 回答跑偏
而解析阶段得到的结构信息,影响远不止于此,它会顺着 RAG 流程一路传导:层级结构能让召回更精准(同名子标题下的不同内容,有了层级才能区分);切片可以顺着章节、段落天然边界智能裁切,避免暴力硬拆破坏语义;等到检索召回阶段,还能依托结构做上下文连带补全,比如召回一个小标题,自动把该标题下的所有内容一并补进来。
解析做得好不好,决定了知识能不能真正”用起来”,这也是本文接下来要重点拆解的事。
演进三阶:文档解析的迭代之路
行业对文档解析的探索,走过了拼凑、通识、原生式建模三段循序渐进的历程
面对”把文件读懂”这道难题,行业里目前走出了三条思路截然不同的路:
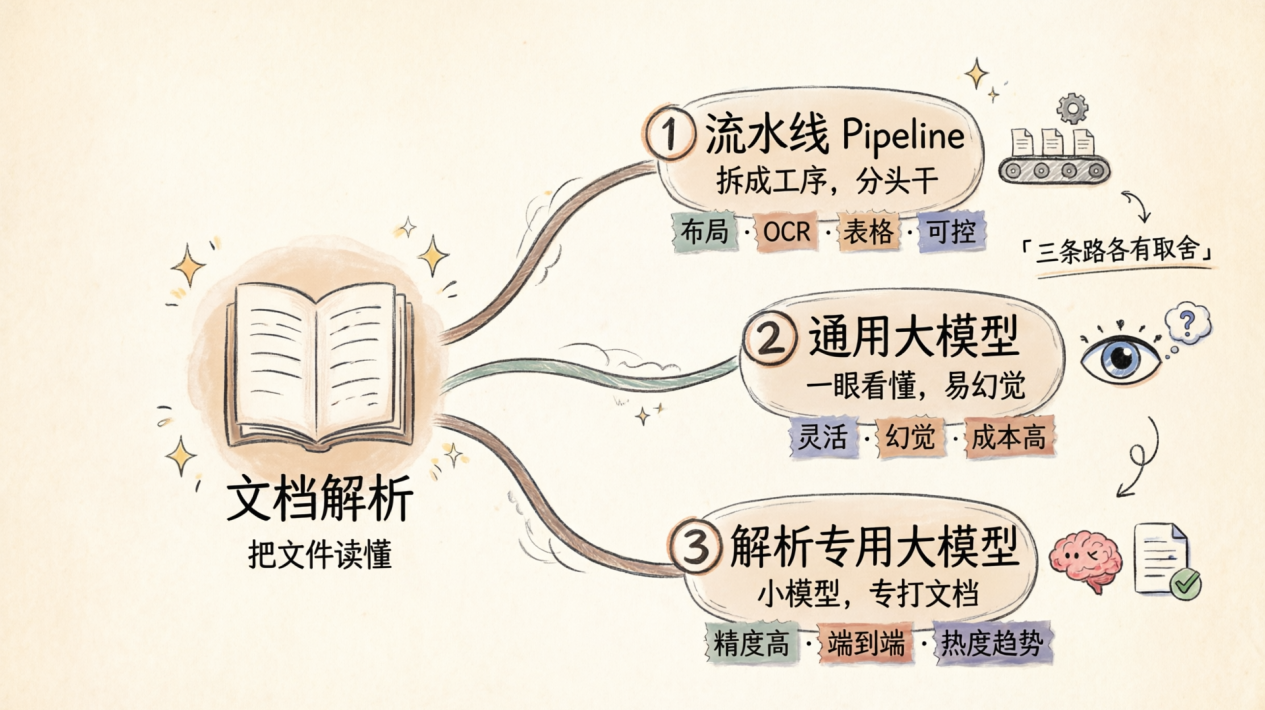
第一条路:流水线(Pipeline),把解析任务拆成一道道工序(图像处理、布局分析、内容识别提取、元素块关系整合),像工厂流水线一样依次执行。每个环节可以单独打磨,出了问题好定位。代价是:错误会一级一级叠加,前一步跑偏,后面全跟着偏。
第二条路:通用大模型,直接让 GPT、Claude 这类通用模型来”看图读文”。跳过了复杂的流水线,但通用模型没有专门针对文档解析优化,遇到复杂排版、大量表格、专业公式,往往力不从心。
第三条路:解析专用大模型,专门为文档理解训练的多模态模型,把整张文档页面直接输入,一步输出结构化内容。既有大模型的理解能力,又针对文档场景深度优化,代价是更大的模型体积、更多的训练数据和计算资源。
三条路各有取舍,下面逐一拆开看。
解析流水线
流水线的思路很直观:既然”把文件读懂”太复杂,就把它拆成若干个专项任务,每一步专注干一件事,依次交接。整个过程像工厂装配线,图像预处理、布局分析、内容识别提取、 表格识别、关系整合等,每道工序各司其职。
这种思路的优点很突出:每个环节都能单独优化、升级,比如觉得OCR识别不准,直接替换OCR模块就行,不用动整个流水线的架构,灵活性拉满。但缺点也同样致命,堪称“一步错、步步错”:前序环节的错误会像多米诺骨牌一样,一路向下传递。比如前一步布局分析错判了表格边界,后面的内容提取就会跟着跑偏,最后可能输出一份“结构看着完整,内容却一塌糊涂”的解析结果,相当于白忙活一场。
流水线各环节也都是不能轻松拿下的:
• 布局分析:现有模型对相似元素类型的区分能力有限,列表、普通文本块、无边框表格,视觉上长得太像,经常分不清;标题层级的判断也容易出错,后续步骤一旦”拿错了骨架”,全链路都会跑偏。
•** OCR**:分两步走,先做位置检测(找到文字在哪),再做文本识别(把字认出来)。两步都有坑:密集文字块、特殊字体、复杂背景都会影响识别质量。
• 表格识别:规整的有线表格还好处理,真正的难点是合并单元格:跨行跨列、嵌套合并、多行内容,机器想完整还原这类复杂结构极其困难。
• 公式识别:分行间公式和行内公式两类。行内公式跟正文混排、没有视觉分隔,起止边界极易识别错;分数、根号、矩阵、多层上下标转成 LaTeX 时层级稍有偏差,整段语义就崩了,相当于“差之毫厘,谬以千里”。
• 图表解析:尚无统一转换标准,大多数方案是半自动或针对特定图表类型定制,通用性有限。
• 元数据提取:这是最容易被忽略的“隐藏宝藏”,包括目录结构、超链接、字体样式、书签层级……这些不在正文里,但在恰当的场景下价值不小:目录可以直接还原文档层级,链接能补全引用关系,字体样式有时能辅助判断标题和正文。不提取,就是白白丢掉了一份现成的结构线索。
• 文本关系整合:所有元素提取完成后,还要按正确的阅读顺序把它们重新串联,尤其是双栏、多栏排版,左栏一段、右栏一段不能混读,图像和表格也要在合理的位置穿插进来,而不是堆在文末。
布局分析
布局分析是后续所有步骤的基础:**先看懂页面的”骨架”,再去提取内容。**它要识别页面上每个元素的类型(文本块、标题、表格、图片、公式……)、位置,以及它们之间的关系。
这件事的技术演进可以分三层看:
第一层· 元素在哪里。 把页面切成块。早期以CNN 为主(R-CNN / Mask R-CNN / YOLO 系列),其中 DocLayout-YOLO[6] 在 YOLO-v10 基础上加了全局到局部感受野模块(GL-CRM),应对大小差异悬殊的元素,是目前工程界的主力。Transformer 路线(BEiT、DiT)全局特征更强但算力也更贵。另外还有基于图(Doc-GCN、GLAM)和基于网格(BERTGrid、VGT)的补充路线[7]。这一层能告诉机器”这里有块内容”,但分不清标题还是图注。
第二层· 元素是什么。 给每块认个语义角色(标题 / 段落 / 页脚 / 题注 / 列表)。标志性工作是 LayoutLM 系列[8-10]:v1 把文本和坐标嵌入结合,v2 加入图像特征,v3 用统一的文本-图像掩码预训练把结构简化到位。“文本 + 布局 + 图像”三合一从此成为多模态文档模型的主流配方。
第三层· 元素之间什么关系。 最新也最难的一层,把区域检测、角色分类、阅读顺序统一建模为”关系预测”。DLAFormer[11](2024)是代表作,用一个端到端 Transformer 同时预测域内、域间、语义角色三类关系,避免多阶段误差传播,在 DocLayNet 等基准上全面领先。2025 年后的 HybriDLA[12] 和DRGG[13] 继续推高指标,目前主要停在研究阶段。
训练数据也在同步进化。PubLayNet[14] 只覆盖 5 类学术版式;M6Doc[15](合合信息 & 华南理工,2023)扩到 74 类、9080 页、7 种文档类型,标注粒度上了一个台阶。但真实业务里的”野生文档”(产品手册、施工图、海报、混排合同)仍然远超这些数据集的覆盖范围。
内容提取
布局分析画好了每块内容的位置和角色,但还没把字”读出来”。到了内容提取这一步,才真正开始跟文字、公式、表格、图表打交道,每种都有自己的门道,得分头处理。
动手之前,有条捷径得先提一嘴:内嵌了文本层的标准 PDF(非扫描件),用 pypdf、PyMuPDF、pdfminer 这类工具可以直接把文字扒出来,不用走 OCR,又快又便宜。
但”能提取”不等于”提取干净”。真实项目里,直接提取翻车的场景比比皆是:
• **字体的坑:**字体子集化或嵌入不规范,抽出来是乱码、方块字、甚至一片空白
• **看得见抽不着:**水印遮住的文字、被其他元素叠压的文本,人眼能看见,工具却给不了
• **混合排版:**同一页里文字和图片掺在一起,文字部分直抽,图里的字必须走 OCR,两条路得同时跑
所以即便拿到的是”带文字的”标准 PDF,老老实实用 OCR 兜底仍是常态。
OCR(光学字符识别)
OCR 是内容提取的基础能力:把图像里的文字,变成计算机能处理的文本。
标准流程分两步:文本检测(在图像里找到哪里有字)→ 文本识别(把找到的字认出来)。两步合在一起叫 text spotting(文字定位识别)。
OCR 的挑战来自两端:一端是复杂版式(密集文字、多列混排、特殊字体),另一端是专项内容(表格里的字、公式里的符号)。通用 OCR 模型和专项模型之间的能力边界,至今仍是工程上需要仔细权衡的地方。
公式提取
数学公式是文档里最”另类”的内容:既不是普通文字,也不是图表,而是一套有严格语法规则的符号系统。提取公式,需要把渲染好的符号图像转换成 LaTeX 或 Markdown 等结构化格式。
最麻烦的不是独立成行的”展示型公式”(视觉上和正文明显分离,比较好检测),而是嵌在段落里的行内公式:字号和正文接近,与周围文字紧挨着,机器很难准确找到它的起止位置。行内公式的识别,至今仍是这个环节最棘手的难点。
表格提取
表格是”结构化知识”最密集的载体,也是最难从文档里完整提取的内容之一。
整个过程分两步:表格检测(找到表格在页面上的位置,与其他内容区分开,不少流水线会直接复用布局分析的结果)→ 表格结构识别(搞清楚内部的行列关系、单元格边界、合并情况)。
结构识别有三条主要技术路线:
• 行列分割法(自顶向下):先定位整个表格,再切分行列。对边界清晰的规整表格很有效,碰到空白多、排列不规则的表格容易出错。进阶版本引入了合并概率估计和 Transformer 全局建模,改善了对复杂单元格关系的处理。
• 单元格检测法(自底向上):先找到每个独立单元格,再拼出整体结构。处理复杂表格更灵活,但计算量大,单元格识别出错会直接影响最终结构。
• 图像到序列法:受 OCR 和公式识别启发,用编码器-解码器架构把表格图像直接转成 LaTeX 或 HTML。对复杂表格适应性最强,但训练难度高,误差传播仍是挑战。
图表提取
图表是文档里”最难被机器理解”的内容,它把数据压缩成了视觉符号,机器看到的只是像素。
图表处理通常经过几个子任务依次完成:图表分类(折线图还是饼图)→ 元素识别(坐标轴、图例、数据点在哪里)→ 数据提取(把视觉图形还原成原始数据或 JSON)→ 图文关联(找到对应的标题说明)。
图表解析目前仍是流水线里最不成熟的环节,缺乏统一标准,大多数方案只能处理特定图表类型。多模态大模型在理解复杂图表上展现出潜力,但如何把大模型的理解能力融入模块化流水线,仍是开放问题。
关系整合
前面几步各自输出了文字、公式、表格、图表,最后这一步的任务,是把散落的碎片拼回成一个有逻辑的整体。
具体做法是利用布局分析阶段得到的空间坐标信息,结合基于规则的系统或专门的阅读顺序模型,还原内容的逻辑流程:哪一段文字在哪个标题下、哪个表格配哪段说明、图注和图片如何对应。
这一步做得好,输出的是一份结构清晰、层级完整、可供后续直接使用的结构化文档;做得不好,输出的就是一堆”看起来对”但逻辑混乱的内容碎片。
通用大模型:一步到位的方案?
文档解析的流水线模块繁多,难免出现衔接问题。于是一个自然的想法应运而生:能否跳过流水线,让足够聪明的大模型“看一眼就读懂”文档?
这正是 GPT-4o、Claude、Gemini、Qwen-VL、InternVL 等通用多模态大模型(VLM)正在做的事情。它们接受图像和文本的混合输入,直接输出结构化内容,不需要单独的布局分析、OCR、表格识别模块,一个模型打通全链路。
这种方案的吸引力显而易见:
• **语义连贯性:**流水线的输出是碎片拼装的结果,而 VLM 在一次推理中完成全局理解,输出的文本在逻辑上更通顺,不会出现”表格被截断在两段中间”这类拼装错误
• **灵活性极高:**同一个模型,换一条 prompt 就能切换任务(从纯文本提取到表格解析到图表描述),不需要为每种内容维护一条独立管线
• **对非标准文档更友好:**海报、宣传册、手写笔记这些让传统流水线束手无策的”野生文档”,VLM 反而能凭借通用视觉理解能力给出还不错的结果
但”看一眼就懂”的代价同样真实:
**幻觉(Hallucination)**是最致命的问题。 这正是文章开头反复提到的那个”命门”(大模型可靠性不足、幻觉频发),在解析这一关上被再次放大。VLM 并不是在”抄写”文档内容,而是在”预测”下一个 token,意味着它有可能自信满满地编造出原文根本不存在的文字。在知识管理场景里,一个被悄悄篡改的数字或术语,比漏提一段话危害大得多。根据 CodeSOTA 在 2026 年发布的 CC-OCR 评测[16]:GPT-4o 的编辑距离(edit distance,把识别结果改成原文所需的最少增删改字符数,越小越准)约 0.02,Claude 约 0.03,看起来差距不大,但 Claude 的幻觉率(0.09%)明显低于 GPT-4o(0.15%)。“更准”与“更少编造”需工程权衡。
高密度长文本是第二道坎。 整页密排文字对VLM的视觉-文本对齐是巨大挑战,部分模型因冻结底层语言模型参数,易出现重复输出、格式错乱、丢失上文的问题,现有对齐方法仍力不从心。
**表格和公式仍是软肋。 **尽管 VLM 能”看懂”简单表格,但遇到多级表头、大面积合并单元格、或者嵌套表格时,输出准确率会明显下降。公式识别也类似,展示型公式勉强能应付,行内公式几乎必错。Reddit热帖[17]精准点出症结:模型将二维表格压成一维token序列,丢失行列关系,无边框表格、多行单元格更是易导致解码崩盘。社区共识是,复杂表格仍需专用模型做后处理。
成本不可忽视。 每页文档都要作为图像输入模型,token 消耗巨大。以 GPT-4o 为例,处理 1000 页文档的 API 费用约 7.5 美元,Claude 约 6 美元,对于动辄数十万页的企业文档库,这是一笔沉重的账单。而且推理速度远慢于传统 OCR 引擎,无法满足实时批量处理的需求。
文档类型覆盖仍有盲区。 当前 VLM 的训练数据和评测基准主要集中在科学论文、教科书等结构化文档上,对于说明手册、工程图纸、报纸版面、古籍扫描件等更复杂的格式,表现参差不齐。M-LongDoc 等新基准正在推动对超长文档理解能力的系统评估,但距离”通用文档解析”的目标仍有明显差距。
通用大模型给文档解析带来了”端到端”的可能性,但目前更适合作为流水线的补充而非替代:在非标准文档、语义理解、快速原型等场景中发挥优势,而把高精度、大批量、零容错的任务留给模块化系统。真正有意思的一条路,是专门为文档解析训练的端到端模型:既想要流水线的精度,也想要大模型的灵活,兼得两路的优势。
解析大模型:专门为文档而生
在文档解析这个需要极致精度的任务上,“差不多”等于”不够用”。那要是把通才换成专才,从头训一个专门为文档解析而生的模型呢?
这正是”端到端解析大模型”(Document-Expert Large Models, DELMs)的思路:保留大模型”一步到位”的简洁架构,但在训练数据、视觉编码器、解码策略上全部针对文档场景深度定制。它们不试图理解整个视觉世界,只专注于一件事:把文档图像精准地变成结构化文本。
从开荒到军备竞赛
这条路线的起点可以追溯到 2023 年。Meta 发布的 Nougat[18]是早期代表作,用 Swin Transformer 编码器搭配 mBART 解码器,首次实现了学术 PDF 直接转 Markdown 的端到端流程,不依赖任何外部 OCR 模块。它证明了一个关键假设:专门的视觉-语言模型可以跳过整条流水线,直接从像素到结构化文本。
2024 年,这条赛道迅速拥挤起来:
• **GOT-OCR 2.0[**19](阶跃星辰)提出了”万物皆字符”的理念:文字、公式、表格、甚至乐谱,全部视为待识别的”对象”。模型用 500 万文本-图像对训练,采用预训练→联合训练→微调的三阶段策略,在复杂图表和非传统内容上超越了此前所有专用模型
• **OmniParser[**20] 将文本解析、关键信息提取、表格识别统一到一个框架里,用两阶段解码器将 OCR 与结构序列处理解耦,推理速度和表格识别精度同时提升
• Fox[21] 引入多套预训练视觉词表(CLIP-ViT + SAM-ViT),不修改预训练权重就能同时处理自然图像和文档数据,把能力边界拓展到多页文档的跨页翻译和摘要
这一阶段的关键突破,是证明了端到端模型不仅能做到”准”,还能做到”全”:从单一的学术论文解析,扩展到了多类型、多页面、多任务。
小模型掀翻大模型:当前的技术竞赛
真正让行业震动的,是 2025-2026 年涌现的一批亚 1.5B 参数的轻量级解析模型,它们在标准基准上全面超越了 GPT-4o、Gemini、Qwen2.5-VL-72B 等体量大出几十倍的通用模型。这在整个 AI 领域都算得上罕见的”以小博大”。
PaddleOCR-VL(百度,0.9B 参数)是这波浪潮的引爆点。它用 NaViT 动态分辨率编码器搭配 ERNIE-4.5-0.3B 语言模型,在 OmniDocBench V1.5 排行榜上以 90.67 的综合分一度拿下第一,全面领先文本、表格、公式、阅读顺序四项核心指标。支持 109 种语言,推理速度比同期模型快出一截,而且可以在 CPU 上运行,甚至做成浏览器插件。后续版本 PaddleOCR-VL-1.5 进一步将准确率推到 94% 以上。
DeepSeek-OCR(DeepSeek)走了一条更有想象力的路。它的核心创新不在”读”,而在”压”:通过视觉编码器将文本图像压缩成极少量的 vision token,压缩比达 10-20 倍,97% 的信息仍可解码还原。它的 DeepEncoder 巧妙地将 SAM-Base(局部注意力)和 CLIP-Large(全局注意力)串联,中间用 16 倍卷积压缩器衔接,让高分辨率图像处理的计算量大幅下降。2026 年初发布的** DeepSeek-OCR-2 更进一步,引入了”视觉因果流”**(Visual Causal Flow):打破传统模型从左上到右下的固定扫描顺序,让模型像人类阅读一样根据内容语义动态决定阅读路径。在 OmniDocBench V1.5 上达到 91.09% 的准确率,阅读顺序编辑距离从 0.085 降到 0.057。
GLM-OCR(智谱 AI / 清华,0.9B 参数)一度刷到 OmniDocBench V1.5 上 94.6 的高分,超过了 Gemini 3 Pro(90.3)和 GPT-5.2。它的秘密武器是多 token 预测(Multi-Token Prediction, MTP):训练时每步预测 10 个 token,推理时平均每步解码 5.2 个 token,吞吐量直接提升 50%。架构上先用 PP-DocLayout-V3 做布局检测,再对各区域并行识别,不是整页”看一遍”,而是分区精读。它还区分了文档解析(输出 Markdown/JSON)和关键信息提取(输出 JSON)两条任务路径,并在训练最后阶段引入了强化学习(GRPO),对文本、公式、表格、关键信息分别设计奖励函数。实际使用下来并没有那么好,对于文档中图片的获取能力还是缺失。
MinerU 2.5-Pro[22](上海 AI Lab,1.2B 参数)是当前的擂主。架构上沿用 MinerU 2.5 的”两阶段解耦”思路:第一阶段在低分辨率下完成布局检测(找到哪里有什么),第二阶段在原始分辨率的裁剪区域上做内容识别(精确读出内容),先看全景再看细节。但 2.5-Pro 的关键改动不在架构,而在数据,论文标题就直接挑明”Data-Centric Document Parsing at Scale”:通过大规模数据工程和训练策略升级,在不动结构的前提下把成绩又往上抬了一截。2026 年 4 月,它在 OmniDocBench v1.6 上拿到** 95.69 **的综合分,正面压过 GLM-OCR(94.6)和 Qwen 3.6 Plus(91.20),稳坐榜首。新版本同时加了图表解析、跨页表格合并、表内图片识别、断段重接等工程化能力,更贴近真实业务场景。这条路给行业的启示也很直接:模型已经够小够快了,下一个突破口在数据,不在堆参数。
小模型为什么能赢?
这些亚 1.5B 模型打败 72B 通用模型,不是侥幸,而是反映了一个深层规律:专业化战胜通用化。具体来说,有三个共同的架构选择在起作用:
1. **两阶段解耦已成共识:**先做布局分析(低分辨率、快速),再做内容识别(高分辨率、精准)。MinerU 2.5/2.5-Pro、GLM-OCR、PaddleOCR-VL 不约而同采用了这个策略。本质上,它们把流水线的”分而治之”智慧,重新嵌入到了端到端模型的内部架构里
2. 视觉编码器为文档定制:通用 VLM 的视觉编码器(如 CLIP-ViT)是在自然图像上训练的,对文字密集的文档并不友好。解析大模型则专门设计了高分辨率、动态分辨率的视觉编码器,能看清 A4 纸上 8pt 字体的每一笔每一划
3. **解码策略做了彻底重新设计:**从 GLM-OCR 的多 token 预测,到 DeepSeek-OCR-2 的视觉因果流,这些模型都在挑战”一次预测一个 token”的传统范式,用更符合 OCR 特点的方式生成输出
而 MinerU 2.5-Pro 在 2026 年的反超还揭示了第四点更”反直觉”的事实:**架构红利吃完之后,数据工程才是下一关。**同样的两阶段解耦结构,仅靠大规模数据筛选、训练策略升级,就能把成绩从 SOTA 再往上拽 1-2 个点。这意味着小模型赛道的竞争已经从”比谁结构更巧”转向”比谁数据更扎实”。
基准测试之外的现实
不过,基准测试上的数字需要冷静看待。OmniDocBench 作为当前最主流的文档解析评测标准,覆盖 9 类文档、1355 页,听起来不少,但相比现实世界的文档多样性仍然有限。它偏重学术论文和教科书,对金融报表、法律文件、保险单据、工程图纸等复杂业务文档覆盖不足。而且评测指标(编辑距离、TEDS、CDM)对标点符号、空格、换行等”无害差异”也会扣分,这意味着得分差距不一定反映真实的解析质量差距。
LlamaIndex 最近的一篇分析[23]直言不讳:“OmniDocBench is saturated”,多个头部模型已经卷到 94-95% 区间,剩下的提升空间退化成边缘案例的修修补补,而不是解析能力的实质进步。真正的硬仗,在基准之外的”长尾文档”里。
95 分之后:下半场重回低谷
入场券,不是毕业证
前面三条技术路线(流水线、通用大模型、解析大模型)在论文和基准测试里看起来都挺像回事。但把它们搬进真实的生产环境,你会发现技术可行和工程可用之间,还隔着三道关卡。
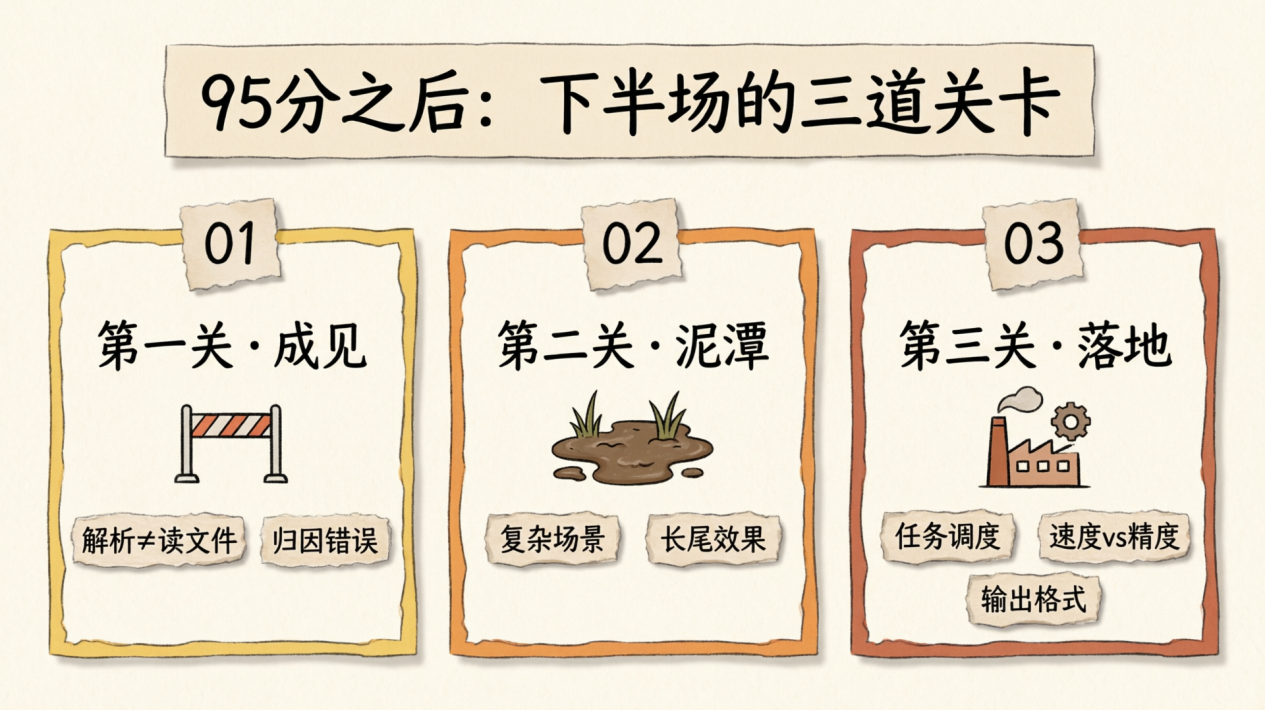
第一关:成见
真到了业务落地的时候,最难的往往不是算法,而是预期管理。
“解析不就是读文件吗?”
这是我们在进行解析项目前期沟通时最常听到的一句。在很多业务方的认知里,文档解析和”打开文件”差不多:Office/WPS 能打开的东西,解析器当然也能读出来,凭什么还要 GPU?
平心而论,这句话在某些场景下确实成立。前文提到的 pypdf、pdfplumber、PyMuPDF 这类工具,对内嵌了文本层的标准 PDF、规范的 Word/HTML,确实能直接抽出文字,CPU 跑跑就够。但解析项目真正要面对的场景,几乎从来不是这种”乖文件”,而是扫描件、混合排版、字体子集化乱码、合并单元格的复杂表格、图文交叉的报告、专业领域的图表和公式。这些直抽工具一上手就会哑火,整条流程被逼回 OCR + 布局分析 + 表格识别 + 关系整合的全套流水线。
我们通常需要给用户做出实在的解释:用肉眼”看懂”一页文档,和让机器”结构化理解”同一页文档,完全是两个量级的任务。 人脑能自动补全模糊的字、推断断裂的表格、根据上下文忽略水印;机器做同样的事,得把前面提到的所有过程都跑一遍(参见解析流水线 章节),每一步都吃算力,少一步整页就读偏。
而且这种”吃算力”并不是流水线独有的。如果是通用大模型那条路,GPT-4o、Claude、Gemini 这种巨型 VLM 单次推理的开销远比一条专项流水线还要重;走解析专用大模型路线,MinerU 2.5-Pro、GLM-OCR 这些 1B 量级的小模型虽然轻了不少,但仍然需要 GPU 才能跑出可用的吞吐,何况还要做布局检测和内容识别两阶段。三条路各有各的精打细算,但没有一条是”白嫖 CPU 就能搞定”的。
业务方看不见这些,决策者也很少有人懂。解析团队遇到的第一道关,往往不是技术难题,而是”零资源约束下的不可能任务”。
[实战手记] 我们的应对策略其实是一套两层调度:
第一层· 按文件特性分流。 服务入口先做一道快速体检:是不是扫描件?文本层完不完整?字体有没有子集化?标准 PDF / 规范 Word / HTML 直接走 pypdf、pdfplumber、PyMuPDF 这类轻量工具,CPU 几秒搞定;判定为扫描件、坏字体、低质量混排的,再调度到 OCR + 布局分析 + 表格识别的重型流水线。能省一步算力,就少烧一份预算。
第二层· 按业务场景定档。 同样一份”重型文件”,不同业务对精度和速度的容忍度天差地别:审计要逐字精确,运营要批量快入。我们把流水线里几个关键能力都做成了可选档位:表格识别引擎可切换(轻量规则 vs 专用模型)、图片是否走 OCR、是否启用图表与标题的语义关联、是否调用大模型对层级结构做增强识别……这些参数对外暴露给用户或上层应用,由它们根据场景按需勾选。
这套解决方案的本质是:不把”高精度全家桶”当默认值,而是让算力消耗跟业务收益挂钩。 用户能看见每一档的成本与效果对比,资源约束自然就不再是”不可能任务”,而是一个透明的工程权衡。
“为什么解析总在出错”
用户在知识库里问问题答案不对,或者文件上传后界面报错,第一反应几乎永远是:“解析没弄好。” 但放到完整的 RAG 链路里看,真相往往不是这样。
完整链路是这条:

任何一环出问题都会让答案跑偏:切片切在表格中间,召回拿到残缺上下文;Embedding 对专业术语不敏感,检索就偏;Rerank 排序失误,正确段落根本没进大模型的输入窗口。再加上业务侧有条硬约束:RAG 问答必须解析成功且入库后才有数据可查,任何一步卡住整条链路就废,所以后台往往把解析、切片、向量化、入库串成一次性流程跑完。结果就是:向量化阶段模型服务挂了,UI 仍然显示”解析失败”。用户看到的”解析报错”,相当一部分跟解析没关系。
[实战手记] 我们项目里逐渐固化了一套**“从后往前归因” **流程:用户反馈”答案不对”或”解析挂了”,不先调解析参数,而是反向逐环节查:先看大模型输入的上下文是否包含正确信息,再看召回是否命中目标段落,再看切片边界,最后才看解析输出。大多数情况下,问题出在解析之后的环节。
第二关:泥潭
认知问题理顺之后,真正的技术硬仗才开始。
复杂场景实录
基准测试里的文档通常是”好学生”:排版规整、清晰度高、格式标准。但真实生产环境里的文档,简直是”全员恶人”:
• 扫描件质量参差不齐:歪斜、模糊、光照不均、手指遮挡,同一份合同,不同人用不同扫描仪扫出来效果就天差地别
• 混合版式文档:一页里同时出现双栏文字、嵌套表格、行内公式、脚注引用、带边框的提示框,布局分析模型需要在一张图上同时处理五六种元素类型
• 非标准表格:跨页表格(表头在上一页)、无边框表格(纯靠空格对齐)、表中嵌表、单元格里塞了一整段话甚至一张图
• 低质量 PDF:字体子集化导致提取出乱码,加密保护导致无法读取,“可编辑 PDF”实际上是图片叠了一层透明文字层(位置还经常对不上)
• 编辑器容错的”善意伪装”:WPS / Word 为了用户体验做了大量容错,格式错乱的表格帮你修复,异常编码的字符帮你替换,文件结构损坏也能勉强打开。用户看到”能正常打开”,就以为文件没问题。但解析器是按规范严格读取的,不会帮你猜用哪种方式读取,典型表现就是”WPS 能打开,一解析就报错”
• “万物皆 PDF”的用户信仰:实际项目里出现频率极高的一类。用户习惯把任何文件都先转成 PDF 再丢进来:PPT 逐页导图再合 PDF、Excel 截图拼 PDF、Word 打印后扫描成 PDF、甚至几十张手机照片直接合一份 PDF……PDF 在用户眼里 ≈ “万能容器”,文件能不能塞进去并不重要,重要的是”格式统一”。问题是,这种用法常常已经远远超出 PDF 格式的合理边界,文本层、字体信息、结构标签全丢,留给解析器的只是一沓被 PDF 壳子包起来的图。解析器没得选,只能整页走 OCR,速度慢、精度掉,工程上也无法针对性的优化
[实战手记] 这些场景没有银弹,只有针对性的”拆弹”。几个我们踩过的坑和对应的处理思路:
•**跨页表格:**在切片阶段引入”回看机制”,当检测到当前页顶部有无表头的表格行时,自动向前查找上一页的表头并拼接
•**混合版式:**对布局分析结果做二次校验,当检测到区域重叠或嵌套时,按照优先级规则(表格 > 图表 > 公式 > 文本)重新分配区域归属
•**字体乱码:**对直接提取的文本做编码检测,当乱码率超过阈值时自动回退到 OCR 路径
•**“万物皆 PDF” 入口护栏:**针对客户随手把各种文件转成 PDF 丢进来的情况,必须在解析入口先架一道”门禁”:规定页面尺寸、图像分辨率、单页面积、文件大小的上下界(过大降采样、过小升采样、过界拒收并告警);同时把翻转矫正(90°/180°/任意角度倾斜)、空白页/无效页过滤、扫描噪点清理这些预处理放到最前面跑完。坏文件提前洗一遍,后面流水线才不会崩得太快
但也有些场景至今仍未很好地解决,比如无边框表格的结构识别、行内公式和周围文字的精确切分。这些是整个行业的共同难题。
效果问题的本质困境
文档解析的效果问题,本质上是个**长尾分布:**80% 的常见文档类型,现有模型和流水线已经能处理得不错。但剩下的 20% 边缘案例,每一个都可能要专门的规则、专门的模型、甚至专门的数据标注才能拿到较为准确的结果。
我们知道提升效果首先要解决的不在 “怎么更好的处理”,而是知道”现在走到哪了(拿到多少分了)”, 这就离不开评估数据集的准备。学术界的 OmniDocBench[24]、PubLayNet、DocLayNet、M6Doc 等公开基准,能告诉你模型或者流水线在测试集上跑多少分,但和真实生产环境遇到的文档还差得太远。OmniDocBench 团队自己后来在 Real5-OmniDocBench[25] 里直接点名了这个 “reality gap”:就算在测试数据集跑出了高分,遇到光照不均的手机扫描件、中英混排的产品手册、内部格式的工程图纸就原形毕露。没有经过生产环境和行业经验沉淀的评估数据集,根本谈不上明确的优化方向,只能像无头苍蝇一样四处打转碰运气。
业内大厂普遍的解法是自建评估集,把真实业务中出过问题的文档脱敏沉淀,标注成回归测试集。但这件事本身很复杂,过程冗长:采集要尊重用户隐私、标注要专家参与、覆盖度要持续补充,很多团队根本撑不到那一步。
即便有了衡量的尺子,从 70 分爬到 90 分还相对容易,靠架构选型和模型升级就能拿下,堆流水线、换 LayoutLMv3、上 DocLayout-YOLO,边际收益肉眼可见。但从 90 分往 95 分走,相当于重新开始爬另一座高山。常见套路无非那几种:按行业重训子模型、加重预处理(歪斜矫正/去噪/多分辨率)、堆后处理规则、模型集成投票、稀有版式合成数据。
代价也清晰:一整套折腾下来,准确率可能从 92 升到 93,端到端吞吐砍半,线上问题排查链路变长,回归测试从两天拖到一周。付出了那么多,回报就是在自家评估集上提升一两个点,而且经常拆东墙补西墙,修好 A 类文档后,B 类文档反而出现回退。
[实战手记] 在实战中我们通常需要和客户进行多次讨论,确定以下问题达成一致共识:是否有数据集,有没有必要建立评估数据集,准确率的指标该怎么定义,准确率目标值是一个成本曲线拐点而不是一个技术目标。同时我们也会给出下面的建议:对大多数文档类型,投入工程量去拼最后这几个准确率点往往不划算,更好的策略是把注意力转移到这四件事上:
1.覆盖面:能处理的文档类型更多一些,比单一类型拿到更高的准确率更有价值
2.降级机制:识别不确定时明确告诉用户”这里可能有问题”,比强装准确好得多
3.反推文档标准化:解析失败的非典型 case,往往不是模型不行,而是企业内部文档本身就没规矩。比如图片/表格标题的格式各写各的(有的标在图上、有的标在图下、有的干脆没有),跨页表格策略五花八门(有的直接断开、有的每页都重复表头、有的拆成”表 1""表 2”)。我们的做法是把这些坑系统地暴露给客户,并给出具体的撰写规范建议,反过来推动企业内部文档标准的收敛。
4.开放人工兜底入口:对那些解析效果不理想、但业务上又必须进入 RAG 问答的文件,光靠模型迭代救不回来。至少需要有方便的兜底入口,例如切片层级的直接编辑通道,业务方可以在 UI 上手动增删切片、调整切片边界、修补缺失的表格内容、补齐图片/表格的标题关联。把最后一公里交给人,比强行让模型扛下所有 case 划算得多。
只有当某类文档是业务核心、值得单独”培养一条流水线”时,再去投入工作量到那最后几分的攻坚
第三关:落地
当解析效果到达了一定程度,要在生产环境里稳定运行,还有实际的问题要解决。
任务管理:解析天生需要调度框架
一份 200 页的 PDF,经过布局分析、OCR、表格识别、关系整合,可能需要跑几分钟甚至更久。当几十个用户同时上传文件,许多问题就逐渐暴露:
• 同步还是异步?同步等待体验太差,异步又需要完善的任务队列
• 用户看不到排队进度
• 任务失败了怎么重试?部分成功怎么处理?中断了怎么恢复?
[实战手记] 我们的方案以及思路如下:
同步 / 异步双入口分流。 对话应用界面里上传的文件,通常都做了大小和格式的硬限制(比如≤10MB 的 Word/PDF),走同步解析接口直接返回结果,用户体感交互需要和”贴张图聊天”差不多。知识库这种允许扔进上百页 PDF、几十兆 Excel、扫描件批量导入的入口,则一律切到异步队列。
异步队列 + 路由调度。 异步链路核心是RabbitMQ:任务入队后立即返回 task ID,前端凭 ID 轮询当前在队列里的位置,至少让用户知道”我排第几个”。任务路由:解析服务做分布式部署后,每个节点的算力配置并不一样:有 GPU 的节点处理重型流水线(OCR + 布局 + 表格识别),没 GPU 的节点专门接简单任务(文本层直抽、Word/HTML 解析)。RabbitMQ 的 routing key 按文件特性把任务派到合适队列,资源利用率和吞吐都能上一个台阶。
任务取消与中断处理。 大任务的”运行中取消”有真实工程价值:一份 200 页 PDF 跑到一半,用户在前端点了取消,光从队列里删任务远远不够,正在占着 GPU 的子流程必须真正停下来,算力才能让给后面排队的任务。我们的做法是给每个解析任务挂一组自定义信号量:前端取消请求落地后,调度器通过信号量通知正在执行的 worker 在最近的检查点退出,并同步前后端任务状态(已取消 / 中间产物是否保留)。异常中断后怎么恢复,目前没有特别漂亮的方案,只能尽量清理已占用的资源,避免拖垮其他任务,同时把中断原因(OOM / 超时 / 上游不可用 / 用户主动取消)回传给前端,让用户至少知道”为什么挂了”。
速度与精度的永恒博弈
用户的需求永远是”又快又准”,但在工程现实中,这两者几乎总是矛盾的:
• 高精度模型(如 LayoutLMv3、专用表格识别模型)推理速度慢,GPU 资源消耗大
• 轻量级方案(如纯规则+OCR)速度快,但遇到复杂版式就错
• 同一个文档,走完整流水线和只走 OCR + 规则,耗时可能差 10 倍
更麻烦的是,不同用户、不同文档类型、不同使用场景的最优平衡点完全不同。给审计团队处理合同需要极致精度,给运营团队批量导入产品说明书只需要 80% 的准确率但速度要快。
[实战手记] 我们的策略是:系统根据文件类型和用户配置,自动选择不同的解析”档位”(快速模式:纯 OCR + 基础规则;标准模式:完整流水线;精细模式:大模型优化、验证)。用户也可以手动切换。本质上是把”速度 vs 精度”的选择权交还给用户,而不是替他们做决定。
保密文件与可视化调试
企业客户的文档经常涉及商业机密,如合同、财务报表、产品说明书等。解析效果不好或者有特殊报错时,无法拿到原文件进行调试。
这种”蒙着眼睛修车”的场景,对解析流程的可视化和可调试性提出了极高要求:
• 流水线每一步的中间结果需要可视化:布局分析画了什么框?OCR 认了什么字?表格结构怎么拆的?
• 每一步中切换不同模型或调整参数后的效果差异,需要能直观对比
• 这些可视化工具本身不能泄露文档内容,最好能在客户环境本地运行
通用解析器的边界:什么时候该”定制”?
有些文件天生不属于”通用解析”的范畴。比如一类特殊的工程图纸:每张图上方固定位置标注了分组名称和组内索引号,下方固定位置标注了图纸标题,格式完全固定,规则完全明确。
用通用解析器处理这类文件,反而是大材小用:模型费了半天劲做布局分析,不如一条正则表达式来得准。但如果为每种特殊格式都写定制解析器,维护成本又会爆炸。
[实战手记] 我们的策略是:当文件格式有明确的、稳定的规则时,规则优先于模型;当规则无法覆盖变化时,模型兜底。 通用解析器负责”大多数”,定制规则负责”特殊的那几种”,关键是要设计好两者的切换机制和优先级。
输出格式之争:Markdown 够不够用?
还有一个容易被低估的生产化决策:解析结果以什么格式输出?
不同技术路线给出了不同的默认答案。大模型路线(GPT-4o、GOT-OCR、Nougat 等)几乎清一色输出 Markdown;流水线系统(MinerU、Unstructured、Docling)则同时提供 Markdown 和元素级结构化 JSON,甚至打包成包含图片文件的 ZIP 资产包。
这不只是”格式偏好”,它直接决定了下游能做什么。
Markdown 的优势在于通用性:人类可读、大模型能直接消费、几乎所有 RAG 系统都能接入。对于”这份合同的甲方是谁?“这类通用问答,Markdown 完全够用。
但 Markdown 也有它的局限性:
• **图片只剩一个链接 **,无法对图片做独立的向量检索、OCR 或多模态问答
• 表格结构被简化,尽管现在支持了html 形式的表格内容表示(合并单元格的问题有了着落),但是相关联的标题和脚注的全部丢失,而且对于某些场景用户更希望看到原文的表格(原文的表格区域截图)增加可信度
• 没有坐标信息,无法实现”点击答案→跳转原文对应位置”的溯源定位
**元素级 JSON **则补齐了这些缺失。以 MinerU 的 middle.json 为例,每个元素都携带类型标记(text/title/table_body/image_body/list/interline_equation 等)、坐标(bbox/poly)、置信度、以及 Block→Line→Span 的层级嵌套。Unstructured 定义了 NarrativeText、Table、Image、FigureCaption 等十余种元素类型并附带页码、坐标和父子关系。Docling 更进一步,用 DoclingDocument 把整个文档建模为一棵结构树:body 管主体内容,groups 管列表和章节分组,furniture 管页眉页脚。
有了元素级数据,图片可以单独裁切做向量化和 OCR,表格可以独立入结构化存储,每个答案都能追溯到原始页面的精确区域。代价是 JSON 体积大(通常是 Markdown 的 3-10 倍),下游系统需要专门的消费逻辑。
本质上:**Markdown 决定了”能问答”的下限,元素级结构化决定了”能做多深”的上限。 **选择只输出 Markdown,就是选择了”够用就好”;选择同时保留结构化数据,就为后续的多模态检索、精准溯源、知识图谱构建打开了大门。
[实战手记] 我们的解决方案如下:
双轨输出:Markdown + 元素级 JSON 共存。 解析服务一次解析、同时产出 Markdown 和元素级 JSON。Markdown 直接喂 RAG 链路做通用问答;JSON 用来构建元素索引:图片单独向量化,表格单独入结构化存储,坐标建索引撑起溯源。两条轨道共享同一次解析,多花的成本有限,但能力上限能提升不少。Markdown 决定”能问答”的下限,JSON 决定”能做多深”的上限。
多引擎插件化 + Adapter 模式。 平台级解析服务里,引擎不会只有一个:学术论文 MinerU 效果好,扫描件需要用更 Paddle OCR 更稳,多语言场景 Mathpix / LlamaParse 准确率更高,调度层按文件类型动态路由。麻烦的是各家输出又大不相同:MinerU 出 ZIP 包(markdown/ + images/ + 自定义 Block-Line-Span 三级嵌套的 middle.json);LlamaParse v2 返回 JSON,图片是有时效的 presigned URL;Mathpix 出 .mmd 扩展语法,图片 base64 内联;Docling 出 DoclingDocument 树形 Pydantic 对象;有些云服务干脆甩一段纯 Markdown,图片链接几小时后就失效。我们的解法是适配器 + 统一中间表示:先定一套平台自己的中间 Schema(统一元素类型枚举 text/title/table/image/formula/list/header/footer,统一元数据字段page_number/bbox/confidence/caption/content,用 JSON Schema 约束),只覆盖核心字段;再为每个引擎写一个 Adapter,把原始输出”翻译”成中间 Schema:ZIP 类先解压定位、纯 Markdown 类主动拉图、JSON 类做字段映射。上层应用只消费中间 Schema,底层引擎随时替换、叠加、A/B 测试都不影响业务逻辑。
图片必须落到自己存储 + 标题显式关联。 无论原始是本地路径、base64 内联还是 presigned URL,Adapter 统一下载到平台自己的对象存储,并把 Markdown 里的图片链接改写为内部地址。另一个容易忽视的点:图片/表格的标题要显式关联回本体。JSON 里 image_caption 和image_body 是独立元素,不挂关系的话,搜标题关键词基本不会命中图片本身;表格的标题和脚注同理。超链接、加粗/斜体(常用来标关键术语)、页面物理尺寸(坐标的前提)这些元数据,也需要放到特定的JSON 字段才能保住。
下一步
身处浪潮之间,夯实地基,择优而变
把 PDF 变成 Markdown 或 JSON,只是数据知识化的第一步。真正的目标是让这些内容进一步变成机器能推理、能关联、能行动的知识。从”读懂文档”到”理解知识”,也有不同方向的尝试。
Agent 驱动的解析:从单次执行到闭环推理
当前的解析系统,不论流水线还是端到端大模型,本质上都是单次执行:输入一张图,输出一段文本,错了要么人工查要么下游兜。
LlamaIndex 把另一种范式总结为 “Agentic Parsing”[26]:解析不再是静态函数调用,而是带规划、反思、自我修正的推理工作流。简单文本走 OCR,复杂表格调专用模型,图表送多模态大模型;结果出来再做一轮质量检查,置信度低的区域自动回溯重试,每一段内容都关联回源文档坐标以便溯源。
论文端已有实证。AgenticIE[27] 用 Planner-Executor-Responder 三段循环处理欧盟建筑合规文档,在 15,000+ 标注实体的实验里 Exact Match 比 GPT-4o 直接提取高 16%、比 GPT-4o-Vision 高 26%,差距来自调度和纠错,不是底层模型更强。DocAgent / MDocAgent[28-29] 则把长文档拆成多角色分工(通用规划 + 文本/图像专员 + 批判 Agent + 汇总),在长文档基准上平均提升约 12%。
也就是说文档理解一次调用搞不定,得能规划、能分工、能有介入修改的机会。Agent 架构正好合适。
从”通用 OCR”走向行业专用解析引擎
另一条路是面向垂直领域的专用解析引擎。金融要验票据查印章,科研要还原公式和分子结构,政务法律要守住版式和脱敏,这些”行业默认知识”通用模型短期内给不出。真正在客户那儿赚到钱的,往往就是这些”专科医生”型引擎。
代表方向各有侧重:金融侧的发票云、RPA 把 OCR + 验真 + 三单匹配做成流水线[30-31];科研侧的多模态文献模型单独处理公式、分子图、实验图表[32];政务法律侧靠印章识别和复杂版面还原吃饭[33]。通用平台也在反向渗透,Adobe Acrobat AI Assistant 往 PDF 里嵌对话式解读和合同比对[34]。
从解析到”AI 友好的知识层”
解析输出的 Markdown / JSON 还是扁平的,企业真正想要的是关联知识 + 可追溯决策:合同里的甲方和财报里的公司是不是同一家?这条特殊条款是谁批的、依据哪条先例?
GraphRAG 那套”抽实体 → 建图 → 检索”曾被当成终点,2026 年这条赛道的重心已经迁走,三种新范式接力,把”知识层”从给人看的库,改造成给 AI 自己读、自己写、自己改的脑子:
• LLM Wiki(Karpathy, 2026)[35]:弃用 RAG,把知识沉淀回一坨结构化 Markdown,由 Agent 负责 ingest / query / lint,跳过 chunk + embedding + rerank 全套流水线。
• GBrain(Garry Tan, 2026.04)[36]:LLM Wiki 的企业级版,Git + pgvector,每条知识分”线上:当前最佳理解 / 线下:追加证据时间线”两层。重点不是召回率,而是让 AI 跨会话保留对组织的连续认知。
• Context Graph(Gupta, 2025)[37]:把企业里真正决定走向的决策轨迹——谁批了哪条例外、参考哪条先例、合同修改背后的博弈过程,将这些隐性信息沉淀为跨实体、跨时间的关系图谱,让 Agent 不仅知道“该怎么做”,更清楚“上次类似情况怎么处理”。
它们共同的信号是:新生的知识从一开始就是 AI 友好的——条目原子化、引用可溯源、变更带时间线。这正是开篇说的”未来文档以机器友好的形式生成”的雏形,也是解析最终退到幕后的方向。
但那一天还没到。 合同还在用 Word 写,报告还在导出 PDF,扫描件还在归档,企业历史里堆着的几十亿份文件没有一份是按 LLM Wiki 格式生出来的。在新工作流彻底接管之前,会长期存在两条轨道:
• 存量轨道:人类格式资料→ 解析 → 结构化知识 → LLM Wiki / GBrain / Context Graph
• 增量轨道:Agent 原生产出的对话、决策、产物 → 直接写入 AI 友好的知识层,无需额外转换
只有当增量轨道彻底压倒存量,解析才会真正退居幕后;在此之前,它就是连接人类文档与 AI 知识世界的唯一桥梁。无论上层技术范式叫什么,其底层根基始终不变:把人类习惯格式的文件,转化为机器能持续维护、复用的结构化知识。
今天的大模型和 Agent 赛道,新技术新项目迭代速度快到惊人,上午还遥遥领先,下午就可能被新突破超越。热点永远追不完,真伪也难以一时分辨。与其押注最新的潮流走向,不如夯实地基后再做决策:归纳沉淀,察觉判断,始终让技术选择回归场景本身,守住真实可落地的业务价值。
文档解析亦是如此。它并不会随着新模型发布就被轻易淘汰,反而始终是所有知识类智能系统绕不开的底层根基。把这一层基础做扎实了,上层无论是搭建智能 Agent、构建知识图谱,还是落地各类垂直检索引擎,业务应用才能真正做到可用、可信,当然这条路还有很长要走。
参考文献
[1]: Gartner. 《2025 年中国数据、分析和人工智能技术成熟度曲线》(Hype Cycle for Data, Analytics, and AI in China, 2025). Gartner Research, 2025.
[2]: 人民日报. 《AI 大模型究竟如何”思考”?》——关于大模型预训练数据规模与幻觉成因的科普报道.https://paper.people.com.cn/rmrb/html/2023-10/24/nw.D110000renmrb_20231024_2-20.htm
[3]: DeepSeek-AI. DeepSeek-V4-Pro / V4-Flash Preview Release (2026-04-24). 1.6T / 284B 参数 MoE,1M token 上下文,预训练 33T / 32T tokens. https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash ; Kili Technology. *DeepSeek V4: Engram Memory, Training Data Strategy & Release Status (2026)*. https://kili-technology.com/blog/data-story-deepseek-v4
[4]: Microsoft. *Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone*, 2024. arXiv:2404.14219 ; *Phi-4 Technical Report*, 2024. arXiv:2412.08905. (以”教科书级”高质量合成与筛选语料训练,小模型在多项基准上反超体量数十倍的通用模型)
[5]: Drenik, G. The AI Paradox: Why World-Class Algorithms Fail On Second-Class Data. Forbes, 2026-04-23. https://www.forbes.com/sites/garydrenik/2026/04/23/the-ai-paradox-why-world-class-algorithms-fail-on-second-class-data/
[6]: Zhao, Y. et al. DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception. arXiv:2410.12628, 2024.
[7]: Zhang, Q., Wang, B., Huang, V. S. J., et al. Document Parsing Unveiled: Techniques, Challenges, and Prospects for Structured Information Extraction. arXiv:2410.21169, 2024.
[8]: Xu, Y. et al. LayoutLM: Pre-training of Text and Layout for Document Image Understanding. KDD, 2020. arXiv:1912.13318.
[9]: Xu, Y. et al. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding. ACL, 2021. arXiv:2012.14740.
[10]: Huang, Y. et al. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. ACM MM, 2022. arXiv:2204.08387.
[11]: Wang, J. et al. DLAFormer: An End-to-End Transformer For Document Layout Analysis. ICDAR, 2024. arXiv:2405.11757.
[12]: HybriDLA: Hybrid Autoregressive-Diffusion Decoding for Document Layout Analysis. 2025.
[13]: DRGG: Document Relation Graph Generation for Layout and Logical Structure. 2025.
[14]: Zhong, X., Tang, J., Jimeno-Yepes, A. PubLayNet: Largest Dataset Ever for Document Layout Analysis. ICDAR, 2019. arXiv:1908.07836.
[15]: Cheng, H. et al. M6Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis. CVPR, 2023. (合合信息 & 华南理工大学)
[16]: CodeSOTA. Claude vs GPT-4o for OCR: I Tested Both (2026). CC-OCR 评测对比, 2026. https://codesota.com/ocr/claude-vs-gpt4o-ocr
[17]: Reddit r/MachineLearning. [D] Why is table extraction still not solved by modern multimodal models? 2025. https://www.reddit.com/r/MachineLearning/comments/1jnjfaq/d_why_is_table_extraction_still_not_solved_by/
[18]: Blecher, L., Cucurull, G., Scialom, T., Stojnic, R. Nougat: Neural Optical Understanding for Academic Documents. Meta AI, 2023. arXiv:2308.13418.
[19]: Wei, H. et al. General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model (GOT-OCR 2.0). 阶跃星辰, 2024. arXiv:2409.01704.
[20]: Wan, J. et al. OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition. CVPR, 2024. arXiv:2403.19128.
[21]: Liu, C. et al. Focus Anywhere for Fine-grained Multi-page Document Understanding (Fox). 2024. arXiv:2405.14295.
[22]: MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale. 上海人工智能实验室, 2026. arXiv:2604.04771. (1.2B 参数; OmniDocBench v1.6 综合分 95.69, 截至 2026/04 居首)
[23]: LlamaIndex. The Cost of Overthinking: Why Reasoning Models Fail at Document Parsing 及 OmniDocBench 饱和度分析. LlamaIndex Blog, 2026.
[24]: Ouyang, L. et al. OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations. CVPR, 2025. arXiv:2412.07626.
[25]: Real5-OmniDocBench: A Full-Scale Physical Reconstruction Benchmark for Robust Document Parsing in the Wild. arXiv:2603.04205.
[26]: LlamaIndex. AI Document Parsing: How LLMs Are Redefining How Machines Read and Understand Documents. LlamaIndex Blog, 2026. https://www.llamaindex.ai/blog/ai-document-parsing-llms-are-redefining-how-machines-read-and-understand-documents
[27]: Colakoglu, G., Solmaz, G., Fürst, J. AgenticIE: An Adaptive Agent for Information Extraction from Complex Regulatory Documents. Zurich University of Applied Sciences & NEC Laboratories Europe, 2025. arXiv:2509.11773.
[28]: DocAgent: An Agentic Framework for Multi-Modal Long-Context Document Understanding. EMNLP, 2025.
[29]: Han, S. et al. MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding. 2025. arXiv:2503.13964.
[30]: 金蝶. 《金蝶发票云:智能综合收票服务》及《金蝶 AI 星辰:小微企业业财税一体化系统》. https://www.kingdee.com/products/fpy_sp.html ; https://www.kingdee.com/product/small ;以及《金蝶基于第四代英特尔® 至强® 可扩展处理器优化智能 OCR 服务性能》白皮书.
[31]: 用友. 《智友 RPA:流程机器人》(用友开发者中心)及《用友 NC Cloud 内置 RPA 机器人——发票识别、三单匹配、自动结账》. https://developer.yonyou.com/product/smart/rpa ; https://rpa.yonyoucloud.com/
[32]: 深势科技. 《Uni-Finder:多模态科学文献大模型》, 2023. 基于自研 Uni-SMT (Uni-Science Multimodal Transformer) 处理论文公式、分子结构图、表格等多模态内容. (业内文献亦有以 “Uni-Parser” 指代该系列)
[33]: 合合信息. 《TextIn 智能文档处理平台:印章识别 / 智能合同审查 / 复杂表格还原》. https://www.textin.com/ ;以及《“AI+OCR”破解复杂场景印章核验》, 中国财经报, 2022.
[34]: Adobe. Acrobat Studio Transforms Productivity and Creativity with AI Agents (Adobe Newsroom, 2026-01) ; Adobe Brings Conversational AI to Trillions of PDFs with the New AI Assistant in Reader and Acrobat (Adobe Newsroom, 2024) ; Acrobat AI Assistant Introduces New Generative AI Features for Contract Management (Adobe Newsroom, 2025-02). https://www.adobe.com/acrobat/generative-ai-pdf.html
[35]: Karpathy, A. llm-wiki. GitHub Gist, 2026. https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f (把 RAG 流水线换成 LLM Agent 维护的结构化 Markdown 文件夹,三件事:ingest / query / lint。X 上传播 1600 万次浏览,引出 Claude Code / Cursor 一系列 LLM Wiki Skill 实现)
[36]: Tan, G. gbrain. GitHub, 2026-04. https://github.com/garrytan/gbrain (Markdown + Git + Postgres/pgvector 的”个人 / 组织级 AI 大脑”。每条知识分”线上:当前最佳理解 / 线下:追加式证据时间线”两层。发布 24 小时 5,400+ stars)
[37]: Gupta, J. AI’s trillion-dollar opportunity: Context graphs. 2025-12. (提出”决策轨迹 / decision traces”概念:跨实体跨时间沉淀”为什么这么做”,让 Agent 拿到的不只是规则,而是”上次类似情况怎么处理的”先例图)
其他参考资料
• 开源流水线解析工具: MinerU(https://github.com/opendatalab/MinerU)、Unstructured (https://github.com/Unstructured-IO/unstructured)、Docling (https://github.com/docling-project/docling)、Marker
• 商业解析服务: Mathpix、LlamaParse (LlamaIndex Cloud)
• 端到端解析大模型: GLM-OCR (智谱)、PaddleOCR-VL (百度)、dots.ocr (小红书)
• 早期布局/OCR 相关: R-CNN / Fast R-CNN / Mask R-CNN、YOLO 系列、BEiT、DiT、Doc-GCN、GLAM、BERTGrid、VGT、DocOwl1.5、Qwen2-VL、UReader、TextMonkey
• PDF 文本直接抽取: pypdf、PyMuPDF、pdfminer
• 多模态长文档评测: MMLongBench、LongDocURL